コラム
データサイエンス入門講座 第2回 データ活用のための結合と集計

データ活用のための結合作業
引き続き、スーパーマーケットのID-POSを題材にして、条件①を満たせるためにどうすればよいかを考えていきます。結合を行なう際には次のような手順で考えていくとよいでしょう。
手順① 表をまたいでデータをつなげるための「キー」を確認
手順② つなげる前に「データを含む対象」にズレがないか確認
手順③ 「最終的に何毎に一行にまとめるか」を決定
手順④ 複数行になる場合は適切に集計
では手順①について考えてみます。顧客マスターはポイントカードを作ってくれた顧客1人につき1行、という形で、その中には氏名、性別や生年月日、住所といった個人情報が含まれていました。一方、販売履歴はレシートに印字される行ごとに、どんな商品を、いつ、誰が、いくらで買ったのか、という形式でした。
両者の間は顧客IDという項目でつなげることができます。これは顧客1人につき必ず1つずつの値で、複数の顧客の間で「IDがかぶる」ということは基本的にありません。このことを専門用語では「ユニーク」あるいは「一意」といいます。たとえば顧客IDが123456 番というデータがレシート側にあった際に、顧客マスターから顧客IDが123456 番のデータを検索すれば、それが男性による購買かどうか、といったことが判別できます。このように複数の表をつなぐための項目を専門用語で「キー」と呼びます。適切な「キー」が存在していれば、つまりエクセル上でVLOOKUP関数を使ったり、データベースに対してJOIN句を含むSQL文を実行したりすれば、少なくとも「1枚の表」というデータ活用のための条件を満たすことができます。
これはあくまで「理想的な状況」であり、実際はそう上手く運ばないケースも多々あります。
結合を阻む「不完全なキー」
そのようなケースは、データを連結するための「キー」が不完全である場合を挙げることができます。最悪なケースは、キーの定義が不確かで、データの管理がアナログすぎるために「フリーテキストで入力された氏名」を使って、顧客マスター側のデータとレシート側のデータを紐づけなければいけない、という状況などです。これは「顧客ID=123456」という形で互いのデータを参照しあうのではなく、「顧客氏名が渡辺和子さん」といった情報をもとに、参照しあわなければならない状態です。
大手スーパーマーケットなどではあまり見かけませんが、個人商店や中小のBtoB企業などでは、ユニークな顧客IDを確実に振らずに、エクセルなどで管理された「フリーテキストだらけの顧客台帳」と、「フリーテキストだらけの販売履歴」という形で、業務のためのデータを管理しているところも数多くあります。「フリーテキストだらけ」でも「顧客台帳」があれば、顧客への連絡業務はでき、「販売履歴」があれば、未収金のチェックや税務署への売上申告という業務はこなせるというわけです。
また大きな問題はこのような「キー」が顧客にとってユニークなものとは限らない場合です。ユニークとは、より正確には、顧客間でIDがかぶることもなく、1人の顧客が複数のIDを持つこともなく、顧客1人と1つのIDが、完全に1対1の関係を持つことです。「氏名」も確かに「個人を特定するもの」ですが、厳密に1対1かというとそうではありません。
たとえば、「同姓同名」の人間がたまたま2人以上、顧客マスターにあれば、購買履歴側のデータにおいて、そのどちらを指すのか特定することができません。また、「表記の揺れ」という問題が生じることもあります。つまり、名字が「渡辺」で、正確な表記が「渡邊」だった場合に、本人やスタッフの気分次第で「渡辺」と略することもあれば、読み間違って「渡部」と違う書き方をしてしまうことがあるかもしれません。名字と名前の間の空白の有無や、その空白は全角か半角かが違う場合もあります。さらに結婚や離婚によって名字自体が変わってしまう、というケースも考えられます。
このような状況は「キー」の管理として最悪なパターンですが、一応顧客を特定するIDが設定されていた場合でも、同様に「連結できない」という問題が生じ得ます。一方のデータではIDが全角、他方では半角ということがあります。あるいは、一方のデータでは「00123456」という8桁の文字列が、他方のデータでは「0000123456」と10桁になってしまっているかもしれません。さらに、数字文頭に0が並ぶ文字列ではなく「123456」という数値として管理されている状況もあります。あるいは特定の業務などの理由で「男性/女性を判別するため末尾にM/Fをつけて管理する」という仕組みを導入し、IDが「123456F」と表示されるという場合も見かけます( 図表1-3)。
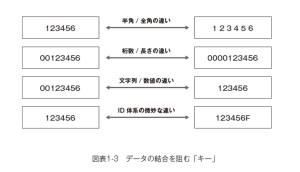
これらは多くの場合「業務のため」に使う限り、それほど問題にはなりません。スタッフの記憶をたどったり、住所などを参照すれば「どちらの渡辺さん」かを特定できるかもしれませんし、名前の表記を間違っても少し失礼ですが、郵便物は届きます。また、名字と名前の間が全角であれ半角であれ、人が見れば「同じ名前」だと認識するでしょう。IDについても全角で書かれた「00123456F」という文字列と「123456」と書かれた数値が同じ意味だ、とシステム管理者なら理解できるかもしれません。
しかし、データ活用ではそうはいきません。個別の業務をこなそうというのではなくデータをまとめて活用しようという場合、たとえば数万ものデータを一括して、加工しなければならないわけです。このような場合に「1つ1つ丁寧に見て何とかする」というのは、活用までに全体としてとんでもない手間がかかる、というのと同じ意味になるからです。
活用のためのデータに思わぬ間違いが含まれないように、つなげるための「キー」はきちんと互いに「まったく同じ」となっているかどうか確認しましょう。
データを含む対象のズレ
「キー」の確認が終わり、もし何か問題があっても何とか互いに「まったく同じ」という状態に整えることができたら、次につなげようとするデータ間で「その中に含む対象」にズレがないかを確認しましょう。
このようなズレがある状況の例として、顧客マスターについては「登録されているすべての顧客のデータ」を使い、販売履歴については「本店のデータ」だけを使う、といったことが考えられます。なぜこんなことをしてしまうのかというと、多くの場合、1人の顧客は何回も来店して、その度にいくつもの商品を買うため、購買履歴の方が顧客マスターよりも何倍もデータが多いからです。そのため「とりあえず本店の購買履歴だけでやってみよう」とか「とりあえず東京の購買履歴だけでやってみよう」「とりあえず直近1か月の購買履歴だけでやってみよう」と考える人はしばしばいます。
もちろん「一部のデータだけで試しにやってみる」という考え方自体は間違いではありませんが、その際注意すべきなのは、組み合わせて活用する顧客マスターについても、同じように「一部」でなければならないことです。
たとえば全顧客のデータと、本店だけの購買履歴を紐づけた場合、どのようなことが起こるでしょうか?「どのような顧客がたくさん買ってくれるか」という分析をした際に、このデータからわかることを正確にいえば、「すべての顧客のうち、本店でたくさん買ってくれるのはどういう人か」という情報でしかありません。当然、「本店の近くに住んでいる顧客はよく本店で買ってくれる」というどうでもいい情報が得られてしまいます。また、このことに気づかず、同じデータで試しに「優良顧客を発見するAI」を作ってみた場合、おそらく同様に本店の遠くに住んでいる人はどれだけロイヤルカスタマーであっても「( 本店では)ほとんど購買してくれない」と判定されてしまうかもしれません。
このようなことがないように、使う購買履歴が「本店における過去1か月分の購買履歴」であれば、使う顧客マスターも「本店において過去1か月に一度でも購買したことのある顧客」あるいは少なくとも「理論上本店において過去1か月に購買できると考えられる顧客」に絞り込まなければいけません。
データの行は活用したい切り口
「キー」と含む対象の確認が終わったら、エクセルのVLOOKUP関数なり、SQLのJOIN句なりを使って、いつでもデータを結合することができますが、次に考えるべきは最終的にデータをどう活用するかという形式です。つまり、結合した後に「何毎に1行ずつにするのか」ということを決めてその形にしていかなければなりません。今回のデータの場合どのような形式が考えられるでしょうか?
顧客マスターの情報を使って、「顧客ごとに1行ずつ」ということもでき、購買履歴の情報を使って「商品ごとに1行ずつ」にしても構いません。たとえば前者の形式であれば「たくさん購買してくれる顧客とそうでない顧客の違いはどこにあるか」と分析することができます
また「優良顧客を自動で見つけてくれるAI」というものを作ることもできます。同様に、商品ごとのデータにすれば「売れる商品とそうでない商品の違いは何か」を分析したり、「商品情報を入力すればそれが今後いくつ売れるかを教えてくれるAI」を作ったりすることもできるかもしれません。
つまり、最終的なデータを「何毎に1行ずつにするのか」ということは、「どのような切り口でデータを活用するのか」と考えることとほぼ同じ意味です。分析や予測について考える章で後述しますが、ざっくり言えば、マーケティングや営業などで顧客のことをよく考えなければいけない場合は顧客ごとに1行、仕入れや企画などで商品のことをよく考えなければいけない場合は商品ごとに1行、というデータ形式がよいでしょう。
ただし、どんな切り口でもいいかというとそうでもありません。すでに皆さんは活用のためのデータの条件として、「数十行以上必要」というものを学んで来たはずです。したがって「男女ごとに1行ずつ」というのではたった2行にしかなりませんので、このような形式のデータは少なくとも本書が考える「活用のためのデータ」ではありません。なぜなら、どんな高度な統計手法を使う分析も、どんなアルゴリズムを使うAIも、私の知る限りたった2行のデータから価値を生むことはないからです。
データ活用のための集計作業
顧客なり商品なりで1行ずつのデータを作ろうとすると、最後に必要となるのが集計作業です。一般的に集計作業というと「今月の売上は合計いくらだったか」とか「登録している顧客の男女比は何%ずつか」といったビジネスの概観をつかむためのものと考えられているかもしれませんが、より高度な分析やAI開発のためのデータを用意するためにも集計作業は必要になってきます。
たとえば顧客マスターと販売履歴を結合した状態から、顧客1人に対して1行ずつ、というデータを用意しようとする場合、1人の顧客に対して複数行存在しうる購買履歴はどのように扱えばよいのでしょうか?1人の顧客が何度も買い物をする可能性は十分にあり、また、1回の買い物ごとに複数の商品を買う可能性もあります。このうち1つだけの購買履歴を残し、ほかは捨ててしまう、というのはあまりにもったいないことです。そこで、複数行をまとめて1行ずつの項目にするために集計を行なうわけです。
エクセルでもデータベースでも、多くのITツールには図表1-4にまとめているような、集計のための関数が用意されています。
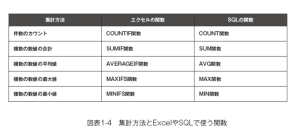
たとえば1人の顧客に対して複数存在する「( 購買した商品の)金額」という数値に対して、どのような集計が考えられるでしょうか?この件数をカウントしたものは「総購買商品点数」すなわち過去に何個の商品を買ったかという情報になります。またこの合計は顧客の「総購買金額」や「ライフタイムバリュー」と考えることができます。
さらに、平均を取れば「平均購買商品単価」と呼ぶことができます。この数値が高い人ほど平均的に高額商品を買ってくれた優良顧客だと解釈できるでしょう。ただし、過去に101商品の購買履歴があって、そのうち100個が100円で、1個だけが100万円だった場合に「平均購買商品単価が1万円」という形で集計してしまうと「100万円という異常な高額商品を買ってくれたことがある」という情報が埋もれてしまいます。この場合、最大値という集計方法を用いて「最高額商品単価」と呼ぶ集計を行なってもよいかもしれません。また、もちろん「最低額商品単価」という集計を考えることもできます。
このようにさまざまな集計方法を考え、「顧客1人つき1行」として求められるデータの形式に加工すると、「( 購買した商品の)金額」という1つの項目から複数の列を生み出すことができます。この列はデータ分析における「説明変数」あるいは、AIにおける「特徴量」と呼ばれる素材となり、数多くあればあるほど、興味深い分析結果や高い精度での動作の可能性が高まります。
顧客ごとの購買金額の違いを「説明するかもしれない変数」として分析に用いたり、優良顧客をAIが識別するための「特徴」として考えたりしようというわけです。複数の項目を組み合わせてから集計したり、集計した項目同士で計算したりしても構いません。
ちなみに今回は「( 購買した商品の)金額」という、もともと「大小が意味を持つ数値」という項目を例に説明しました。これ以外の項目はどう扱えばいいでしょうか?購買履歴の方には「どんな商品を」「いつ」買ったか、という項目も含まれていますが、前述の通りこれらは「( 大小が意味を持つ)数字」でも、「( せいぜい数十個程度への)分類」でもありません。次節ではこうした項目をどう扱うかを説明します。このような項目についても「数値化と再分類」という手順を踏めば、データ分析のための「説明変数」や、AIに用いる「特徴量」という形で利用できるようになります。
データ分析や活用、DX推進に関するお悩み、弊社製品の機能についてご興味のある方は、お気軽にお問い合わせください。