コラム
データサイエンス入門講座 第18回 ズルのできない予測精度の検証方法(1)

「精度100%の予測」といわれたら、まず疑うべきこと
適切な課題を設定できれば、予測モデルもAIも開発できるようになります。ここまでの具体化ができていれば、統計解析や機械学習の専門家でなくても、日本国内だけで100社以上あるという機械学習の開発を請け負う会社に依頼すれば、少なくとも何のアウトプットも出てこないということはありません。
最後の問題は、社内の技術者であれ社外の技術者であれ、あるいは自分自身でも、どのぐらいの精度で予測し、どの程度最適な選択肢を提示できるかを確認することです。これらが「現在の経験と勘による判断よりも高性能」、または「人間がやった場合と比べてそう遜色ない」という水準であれば、課題設定が間違っていない限り、大きな価値を生むことでしょう。今後「このままの状態が続く」という仮定が崩れるような変化に対応するため、定期的なメンテナンスが必要になる可能性はありますが、試験的に導入してみる価値は間違いなくあります。
一方で、予測モデルやAIの精度が、人間と比べてあまりに劣るようであれば開発作業をやり直さなければなりません。予測に必要なデータが他に考えられないか検討し、収集して、アルゴリズムや細かいオプションなどを変えてみて、精度の出る方法がないか検討しましょう場合によっては、実際の予測結果を見てみることで、初めて自分たちが無謀な挑戦をしようとしていたことに気づくこともあります。
性能評価の結果如何で、その後取るべき方向は変わってくるわけですが、問題はこうした開発作業を依頼した技術者が本人の誠実さはさておき、少なくとも「予測精度を高く見せた方が得」という立場にいることです。本人の無知によるものか、意図的かはわかりませんが、納品された予測モデルやAIが「開発時に示されたような性能で動作していない」ということがしばしば起こります。それは、たいていの場合、予測モデルやAI開発に使ったデータのみに「過剰に」フィットさせて、見かけの上では高い精度を示したものの、むしろその後の新しいデータに対しての精度が下がってしまう、という現象が起こってしまっているのです
過学習(オーバーフィッティング)の例
このような現象のことを過学習とか過適合、あるいはオーバーフィッティングと呼びます。単純な例として、次表に示すように、メーカーが新製品の発売前にバイヤーを集め、100点満点で製品を評価してもらった結果の平均値から、新製品が発売後1カ月間でどれほど売れるかと予測する状況を考えてみましょう。
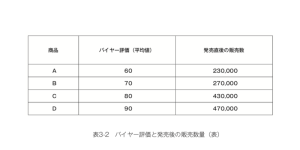
人間が見ればグラフを見ただけで「何となく右肩上がりだな」というトレンドが見えますし、その直感に基づいて試しに単回帰分析という、直線的に横軸と縦軸の一番あてはまりのよい関係を考える統計手法を使ってみた結果もあわせて示します。(図表3-2)
慣例的に数学では横軸をx、縦軸をyで示しますので、今回の場合はxがバイヤーからの評価の平均点、yが発売後の販売数になります。したがってこのトレンドを示す直線の式がy=8,800x-310,000ということは、バイヤーからの評価が1点上がるごとに8,800個ずつ発売後の販売数が増える、という傾向を示しています。また、この式に基づくとバイヤーからの評価が平均60点なら8,800×60-310,000という計算から218,000個ほど売れるはずだ、と予測できます。同様に、70点なら306,000個、80点なら394,000個で90点なら482,000個ほど売れるはずだということになります。
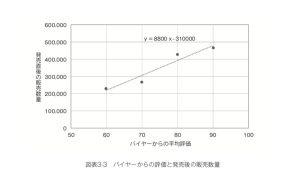
このような数少ないデータでもこれほどクリアなトレンドがあれば、この「1点あがるごとに8,800個ずつ売れる」という結果は「たまたまのバラつきだけで出るようなものではない」と統計的に判断されるようなp値が得られます。(図表3-3)
ただし一方で、この予測は「完全に正確なもの」というわけではありません。バイヤーの評価が平均70点だったものは270,000個ほどしか売れていませんので、実際の値は予測値より3万個以上少ない、ということになります。同様に平均80点だったものは430,000個も売れていますので実際の値は予測値よりも3万個以上も多くなっています。
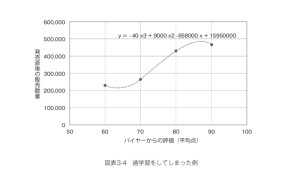
付き合いの長いバイヤーの評価とはいっても「たまたま市場を読み違える」とか「たまたま好みが市場とズレる」ということもあるでしょう。それ以外にも、たまたま広告がウケたとか、どこかのメディアで大きく取り上げられたといった事情もあるでしょうから、バイヤーの評価だけで完璧に予測できるとは限りません。この程度の予測値と実測値のズレが生じることは十分にあり得ます。(図表3-4)
しかし、いたずらに出てきた予測精度を問題視して、とにかく予測値と実際の値とのズレがほぼゼロになるようにしようとすると、過学習の問題が生じてしまうことが多々あります。直線ではなく曲線状になるように、高校で習う3次関数で予測するとまったくズレずに完全な当てはめができるようになります。
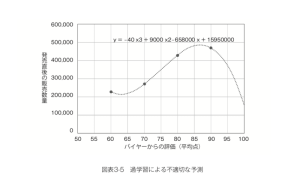
しかしこの「ズレの小ささ」は健全な状態ではありません。新たに新商品を開発したところ、調査に参加したバイヤー全員が大満足でまさかの平均100点、という素晴らしい商品が生まれたとします。このとき、先ほどの直線の式からは「発売後57万個売れる」という予測値が得られます。一方でこの3次関数は90点を超えた時点ですでにピークを越えて販売数量が落ち始める、動きを示しています。実際にこの3次関数に「xが100」という値を用いると、なぜか平均100点というこれまでにない素晴らしい商品であるはずなのに、たった15万個しか売れない、という考えにくい予測値が得られてしまいます。(図表3-5)
これらは、わかりやすいように1つの説明変数から1つの目的変数を予測しようとした例なので、グラフを見れば誰でもその間違いに気づくことができます。しかし複数の説明変数を用いた統計解析や、機械学習ではこのように視覚化することができませんし、特に機械学習では中身がブラックボックスとなるような、「解釈はしにくいけどとにかく予測値と実際の値のズレが小さくなるように」という計算を行うため、過学習を起こしているかどうかについてさらに確認が困難です。
データ分析や活用、DX推進に関するお悩み、弊社製品の機能についてご興味のある方は、お気軽にお問い合わせください。